- Published on
Lofi Music Generation with LSTM model
- Authors

- Name
- Melody Koh
Introduction
Hohoho, welcome to my first NLP project that I am excited to work on. LoFI music playlist has always been my go-to study buddy ever since my college days. The blend of classical melodies, gentle drum beats, jazz tunes, and piano chords creates an ambiance of nostalgia that I find deeply calming.

How I came up with the idea
The idea of building a LoFi music generator first came up to me when I get to learn RNN and LSTM after taking the Deep Learning Specialization offered by deeplearning.ai. It sparked my interest upon discovering LSTM and its potential application in music generation. As a fan of lofi music, I thought it would be a great idea to build a lofi music generator using an LSTM model. However, I have limited knowledge in music theory and I have never worked with music data before, so I was contemplating whether I should proceed with this project. But I decided to give it a try and see how it goes. I started to research on music theory and their representation, what notes are, what chords are, and how they are represented in music. The youtube video, Music Theory Concepts for Melody Generation by Valerio Velardo was very helpful in understanding the basics of music theory and how music is represented in MIDI files. I started to look for music datasets and found the MIDI dataset from Zachary Katnelson a perfect fit for my project, as it contains a collection of lofi music in MIDI format.
What is MIDI?
MIDI stands for Musical Instrument Digital Interface. It is a technical standard that describes a protocol, digital interface and connectors and allows a wide variety of electronic musical instruments, computers and other related devices to connect and communicate with one another.
Tech Stacks
music21
Music21 is a Python toolkit used for computer-aided musicology. In this project, music21 is used to parse the datasets and extract the notes and chords from the MIDI files. After that, they are translated into musical notation.
Keras
Keras library is used to build and train for the LSTM model. Once the model is trained we will use it to generate the musical notation for our music.
Tone.js
I would like to create an interactive music player for our generated music. Did some research and found Tone.js, a Web Audio framework for creating interactive music in the browser, which provides a perfect fit for my project.
Why LSTM?
LSTM (Long Short-Term Memory) is a type of Recurrent Neural Network Architecture (RNN) that is well-suited to learn from sequences of data. It is capable of learning long-term dependencies and is widely used in sequence prediction problems such as language modeling, translation, and music generation. LSTMs are designed to avoid the long-term dependency problem in RNNs, where the network is unable to learn from information that is further back in the sequence, this makes LSTM a suitable model for this project.
Data Preprocessing
The MIDI files contain a collection of notes and chords, however a model simply cant understand what they are, we need to extract these notes and chords and covert them to integers in order to train our model. As mentioned above, music21 library can helped us with this. In other words, a note will be saved as a Note object, a chord will be saved as a Chord object, and a rest will be saved as a Rest object. Music21 stores a hierachy of musical elements, where a Score contains Parts, and each Part contains Measures, and each Measure contains Notes, Chords, and Rests. It may be seem daunting at first for a music beginner to wonder what all these phrases were. To understand them, let's look at the diagram below.
 Diagram above describes the musical representation of the hierachy for music21. The orange box that covers the whole is highlighted as
Diagram above describes the musical representation of the hierachy for music21. The orange box that covers the whole is highlighted as Scores, green are the music Parts, and inside the Measures, which are highlighted as Indigo, we have 6 blue squares, indicating the Notes, these Notes are the one that the model will need to predict for. Music21 has this powerful parse() function which could convert our dataset into a Music21 stream object. Using that stream object we get a list of all the notes and chords in the file.One Hot Encoding
C4 is mapped to 60, D4 is mapped to 62, and so on. With this, from keras.utils import to_categorical can be used to encode the notes, chords, and rests. We append the pitch of every note object using its string notation since the most significant parts of the note can be recreated using the string notation of the pitch. And we append every chord by encoding the id of every note in the chord together into a single string, with each note being separated by a dot, as represented by the diagram below. 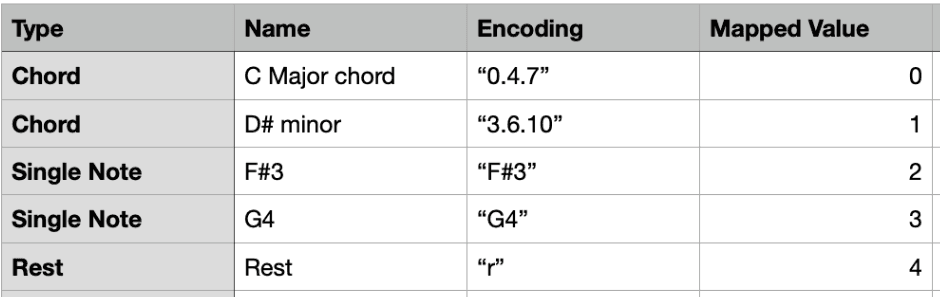
Model Architecture
Now it's time for the training process. LSTM will act as the core structure of our model. It contains 4 different types of layers:
- LSTM layers: takes a sequence as an input and can return either sequences
return_sequences=True - Dropout layers: regularisation technique that consists of setting a fraction of input units to 0 at each update during the training to prevent overfitting.
- Dense layers: a fully connected layer that performs a linear operation on the layer’s input
- Activation layers: applies a
softmaxactivation function to an output.
model = Sequential()
model.add(LSTM(
512,
input_shape=(network_input.shape[1], network_input.shape[2]),
recurrent_dropout=0.3,
return_sequences=True
))
model.add(LSTM(512, return_sequences=True, recurrent_dropout=0.3,))
model.add(LSTM(512))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
A brief overview of LSTM architecture
The architecture of an LSTM can be visualized as a series of repeating “blocks” or “cells”, each of which contains a set of interconnected nodes. Here’s a high-level overview of the architecture:
- Input: At each time step, LSTM takes in an input vector,
x_t, which represents the current observation or token in the sequence. - Hidden State: LSTM maintains a hidden state vector,
h_t, which represents the current “memory” of the network. - Cell State: LSTM also maintains a cell state vector,
c_t, which is responsible for storing long-term information over the course of the sequence. - Forget Gate: takes in the previous hidden state,
h_{t-1}, and the current input,x_t, and outputs a vector of values between 0 and 1 that represent how much of the previous cell state to “forget” and how much to retain. - Input Gate: takes in the previous hidden state,
h_{t-1}, and the current input,x_t, and outputs a vector of values between 0 and 1 that represent how much of the current input to “accept” and how much to add to the cell state. - Output Gate: takes in the previous hidden state,
h_{t-1}, and the current input,x_t, and the current cell state,c_t, and outputs a vector of values between 0 and 1 that represent how much of the current cell state to output as the current hidden state, h_t. This gate allows the LSTM to selectively “focus” or “ignore” certain parts of the cell state when computing the output.
Music Generation
After training the model, we will start by picking a random index in the list as our starting point, we will also need a mapping function to decode the output of the network. The function will map from numerical data to categorical data (from integers to notes). We chose to generate 500 notes using the network since that is roughly 2 minutes of music and gives the network plenty of splace to create a melody.
For each note that we want to generate we have to submit a sequence to the network. The first sequence we submit is the sequence of notes at the starting index, and for every subsequent sequence that we use as input, we will remove the first note of the sequence and insert the output of the previous iteration at the end of the sequence. To determine the most likely prediction from the output of the network, we extract the index of the highest value. The value at index X in the output array correspond to the probability that X is the next note. Figure below could help to explain this.
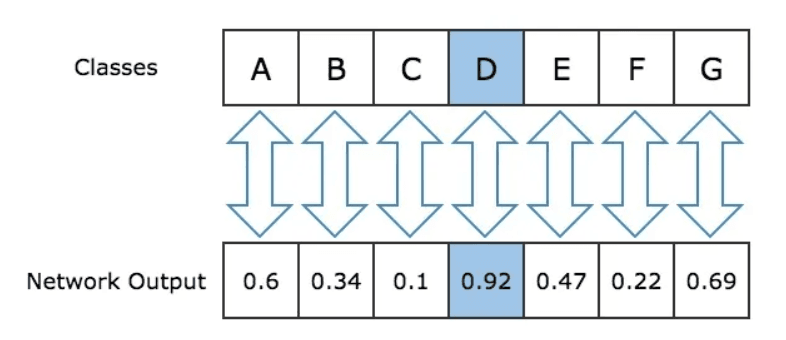
Next we collect all the outputs from the network into a single array. Now that we have all the encoded representations of the notes and chords in an array, we can decode them and create an array of Note and Chord objects. After decoding, we have a list of notes and chords generated by the network we can create a Music21 Stream object using the list as a parameter, Then finally to create the MIDI file which contains the music generated by the network we use the write function in music21 toolkit to write the stream to a file.
midi_stream = stream.Stream(output_notes)
midi_stream.write('midi', fp='test_output.mid')
Conclusion
And that's how the LoFi music generator was built. For the code implementation, you can check out my Github Repository here, and here is the link for the webplayer I built. I have a lot of fun building the LSTM model and working with Tone.js, hope you enjoy the music generated by the webplayer too. Thank you for reading!

Acknowledgements
- How to Generate Music using a LSTM Neural Network in Keras by Sigurour Skuli
- Melody Generation with RNN-LSTM - Youtube Playlist by Valerio Velardo
- Loaf AI Github Repository by Lawreka
- Avengers Movie Dialogues are obtained from here
- Nature and Drum Beats Sound Effects are obtained from Pixabay